Models
In the modeling phase, we explored a few model-feature combinations. We started with simple logistic regression plus LBP and HOG feature, both of which give us ~80% accuracy. Later we also tried SVM and pre-trained ResNet models, the accuracy, precision, and recall are improved to ~90%. The best model we found is the neural network model with LBP feature, which gives us ~92% accuracy and f1-score for the Canada dataset that has higher data quality than US dataset.
Neural Network + LBP
Accuracy: 0.9238095238095239
precision recall f1-score support
nowildfire 0.92 0.90 0.91 282
wildfire 0.92 0.94 0.93 348
accuracy 0.92 630
macro avg 0.92 0.92 0.92 630
weighted avg 0.92 0.92 0.92 630
Logistic regression with LBP features Only
Accuracy: 0.8031746031746032
precision recall f1-score support
nowildfire 0.80 0.75 0.77 282
wildfire 0.81 0.85 0.83 348
accuracy 0.80 630
macro avg 0.80 0.80 0.80 630
weighted avg 0.80 0.80 0.80 630
Categorical Cross-Entropy Loss: 0.5705689908378812
Logistic regression with HOG features only
Accuracy: 0.807936507936508
precision recall f1-score support
nowildfire 0.80 0.76 0.78 282
wildfire 0.81 0.85 0.83 348
accuracy 0.81 630
macro avg 0.81 0.80 0.80 630
weighted avg 0.81 0.81 0.81 630
Categorical Cross-Entropy Loss: 0.6830750477393924
SVM + LBP
Accuracy: 0.9206349206349206
precision recall f1-score support
nowildfire 0.92 0.90 0.91 282
wildfire 0.92 0.94 0.93 348
accuracy 0.92 630
macro avg 0.92 0.92 0.92 630
weighted avg 0.92 0.92 0.92 630
SVM + ResNet (or VGG-16)
Accuracy: 0.9174603174603174
precision recall f1-score support
nowildfire 0.92 0.89 0.91 282
wildfire 0.91 0.94 0.93 348
accuracy 0.92 630
macro avg 0.92 0.91 0.92 630
weighted avg 0.92 0.92 0.92 630
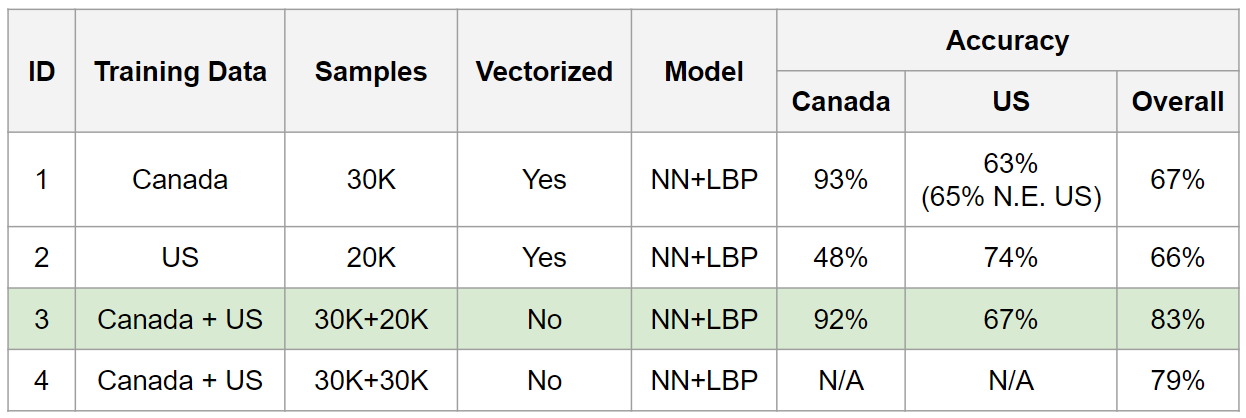
We conducted an investigation into the potential advantages of combing datasets from both the US and Canada with the objective of enhancing the model's generalizability. As illustrated in the table below, the hybrid model incorporating data from both countries demonstrates the highest overall accuracy. While the test accuracy for the Canada dataset remains consistently high, a slight degradation is observed for the US dataset. The supposition for this decline in accuracy is rooted in the hypothesis that the US dataset possesses lower data quality, consequently resulting in diminished model performance. This inference is supported by a comparative analysis between the third and fourth models in the table, where the overall accuracy experiences a 5 percentage point decrease following the inclusion of an additional 10,000 US data samples, while keeping other parameters and configurations unchanged.